Appearance
第5章 Session 与对话管理
"上下文窗口是 Agent 系统中最昂贵的共享资源——每一条消息都在与系统提示、工具结果和对话历史争夺同一块寸土寸金的 token 预算。会话管理的本质不是存储,而是取舍。"
本章要点
- 理解会话生命周期:创建、活跃、压缩、归档的完整状态机
- 掌握上下文窗口管理:滑动窗口、智能压缩、预算分配策略
- 深入记忆系统:短期记忆、长期记忆与跨会话知识持久化
- 理解多会话并发隔离与写锁机制的设计权衡
你和一位老朋友在咖啡馆聊天。聊到一半去了趟洗手间,回来继续之前的话题。你的朋友不会茫然地问"你是谁?我们在聊什么?"——因为她记得上下文。这件事对人类如此自然,自然到你从未想过它需要任何"工程"。
但对 AI Agent 来说,这恰恰是最深层的工程挑战之一。
🔥 深度洞察:上下文管理是信息论问题
大多数开发者把上下文管理当作"字符串截断"——窗口满了就砍掉最早的消息。这就像一个图书馆满了就烧掉最旧的书。正确的思维方式是信息论:每条消息携带的信息量(熵)不同。"你好"几乎没有信息量,而"API Key 存放在 /etc/secrets/prod.key"的信息密度极高。好的上下文压缩不是均匀截断,而是像优秀的编辑一样——保留高信息密度的内容,压缩冗余的寒暄,在有限的"版面"内最大化信息传递效率。这就是为什么 OpenClaw 的 Context Engine 不用简单的滑动窗口,而用智能摘要——因为最优的上下文管理策略,本质上是一个有损压缩问题。
LLM 本身是彻底无状态的。每次 API 调用,你都必须把完整的对话历史作为输入传入——就像一个每隔五分钟就失忆一次的人,你必须不厌其烦地把之前说过的话全部重复一遍。这意味着系统必须为每一个用户、每一个通道、每一个会话,持久化保存完整的对话状态。当一个用户在 Telegram 上说"继续我们昨天的讨论"时,Agent 需要在毫秒内找到正确的会话、加载正确的历史、在有限的上下文窗口内精心裁剪消息——与此同时,另外 49 个并发对话也在等待同样的服务。
上一章我们剖析了 Provider 抽象层如何屏蔽模型差异。既然模型调用的管道已经打通,下一个自然而然的问题是:调用模型时送进去的"对话历史"从哪里来? 本章进入更深层的水域——OpenClaw 如何管理成百上千的并发对话?Context Engine 如何在寸土寸金的上下文窗口中做出最优的信息取舍?记忆系统又如何让 Agent "记住"跨越数天甚至数月的交互?
5.1 会话生命周期
5.1.1 Session Key:会话的全局坐标
每个 Session 通过一个结构化的 Session Key 唯一标识。Session Key 不是简单的 UUID,而是编码了会话的通道来源、聊天类型和 Agent 归属信息。
Session ID 的验证逻辑位于 src/sessions/session-id.ts:
typescript
export const SESSION_ID_RE =
/^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$/i;
export function looksLikeSessionId(value: string): boolean {
return SESSION_ID_RE.test(value.trim());
}但 Session Key 的结构远比 UUID 丰富。一个典型的 Session Key 形如:
text
agent:main:telegram:direct:123456789
agent:main:discord:group:987654321
agent:main:subagent:a1b2c3d4-e5f6-...前缀 agent:<agentId>: 将会话绑定到特定 Agent,后续部分编码通道和聊天类型。
关键概念:Session Key(会话键) Session Key 是 OpenClaw 会话系统的全局坐标,编码了 Agent 归属、通道来源和聊天类型。它不是随机 UUID,而是结构化标识符(如
agent:main:telegram:direct:123456789),使得同一用户在不同通道、不同聊天类型下拥有独立的会话隔离,同时支持按维度查询和路由。
实战场景:跨通道上下文保持
小明在 Telegram 上和 Agent 讨论了一个 API 设计方案,随后切换到公司的 Discord 群继续讨论。在大多数 Agent 框架中,Discord 上的 Agent 会完全不记得 Telegram 上的对话——因为它们是两个独立的 Session。
在 OpenClaw 中,这两个通道分别创建了
agent:main:telegram:direct:xiaoming_123和agent:main:discord:group:team_456两个 Session。虽然 Session 本身是隔离的(这是正确的安全设计——群聊的上下文不应该泄露到私聊),但 OpenClaw 提供了两种机制来桥接这种隔离:
- 记忆系统:Agent 可以将重要的结论写入长期记忆(
MEMORY.md或向量记忆库),在另一个 Session 中通过语义搜索检索回来- 工作区文件:Agent 在 Telegram 会话中创建的文件(如
api-design-draft.md)对所有 Session 可见,Discord 会话中可以直接引用这种设计体现了一个关键权衡:Session 隔离保证安全,共享记忆提供连续性——两者并不矛盾,而是在不同的层次上解决不同的问题。
5.1.2 Session 生命周期事件
图 5-1:Session 生命周期状态机
下图展示了 Session 从创建到销毁经历的所有状态转换。颜色编码:🟢 绿色 = 稳定态,🟡 黄色 = 处理中,🔴 红色 = 关键操作,🔵 蓝色 = 终态。状态转换基于 session-lifecycle-events.ts 中的事件系统和 session-key-utils.ts 中的会话类型判别逻辑。
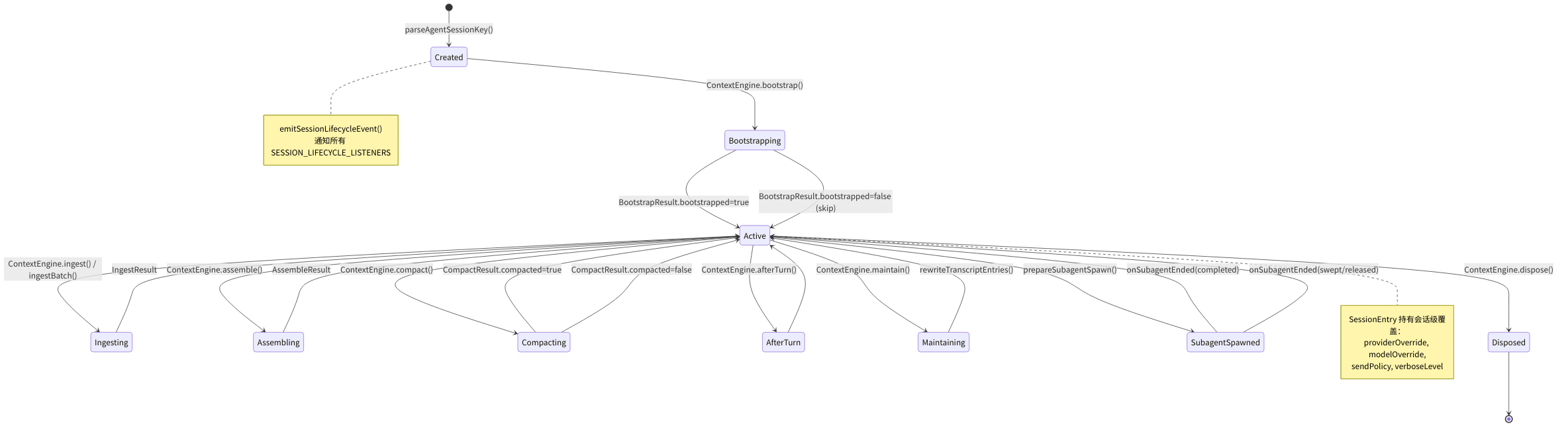
⚠️ 常见陷阱:忘记清理事件监听器导致内存泄漏
onSessionLifecycleEvent()返回一个取消函数。如果你在插件中注册了监听器但忘记在插件卸载时调用取消函数,会导致监听器永远驻留在内存中,每次会话事件都触发已废弃的回调:typescript// ❌ 错误:注册后不保存取消函数 onSessionLifecycleEvent((event) => { /* ... */ }); // ✅ 正确:保存并在适当时机调用取消函数 const unsubscribe = onSessionLifecycleEvent((event) => { /* ... */ }); // 在插件卸载或不再需要时: unsubscribe();
src/sessions/session-lifecycle-events.ts 定义了会话生命周期的事件系统:
typescript
// src/sessions/session-lifecycle-events.ts — 发布-订阅模式
export type SessionLifecycleEvent = {
sessionKey: string; reason: string;
parentSessionKey?: string; label?: string; displayName?: string;
};
const SESSION_LIFECYCLE_LISTENERS = new Set<SessionLifecycleListener>();
// 订阅:返回取消函数,防止内存泄漏
export function onSessionLifecycleEvent(listener: SessionLifecycleListener): () => void {
SESSION_LIFECYCLE_LISTENERS.add(listener);
return () => SESSION_LIFECYCLE_LISTENERS.delete(listener); // cleanup
}
// 发布:try/catch 隔离每个 listener,确保一个异常不影响其他
export function emitSessionLifecycleEvent(event: SessionLifecycleEvent) {
for (const listener of SESSION_LIFECYCLE_LISTENERS) {
try { listener(event); } catch { /* best-effort, 不传播异常 */ }
}
}这是一个经典的发布-订阅模式实现。几个设计要点:
- 返回取消函数:
onSessionLifecycleEvent返回一个 cleanup 函数,调用者可以在不需要时取消订阅,防止内存泄漏 - 错误隔离:
try/catch包裹每个 listener 调用,确保某个监听器的异常不影响其他监听器 - parentSessionKey:支持会话的层级关系——子 Agent 的会话可以追溯到父会话
5.1.3 模型覆盖与会话级配置
每个 Session 可以独立覆盖其使用的模型。src/sessions/model-overrides.ts 实现了这个机制:
typescript
// src/sessions/model-overrides.ts — 会话级模型切换
export type ModelOverrideSelection = {
provider: string; model: string; isDefault?: boolean;
};
export function applyModelOverrideToSessionEntry(params: {
entry: SessionEntry; selection: ModelOverrideSelection;
}) {
// 切换模型时必须清除旧的运行时状态和上下文窗口缓存
// 否则新模型可能继承旧模型的 contextTokens,导致窗口估算错误
if (selectionUpdated) { delete entry.model; delete entry.contextTokens; }
}当用户通过 /model 命令切换模型时,系统不仅更新模型选择,还清除所有关联的缓存状态(运行时模型信息、上下文窗口大小),确保下次运行使用全新的模型参数。
5.1.4 发送策略
src/sessions/send-policy.ts 控制会话的消息发送权限,这是多通道场景下的安全机制:
typescript
export type SessionSendPolicyDecision = "allow" | "deny";
export function resolveSendPolicy(params: {
cfg: OpenClawConfig;
entry?: SessionEntry;
sessionKey?: string;
channel?: string;
chatType?: SessionChatType;
}): SessionSendPolicyDecision {
// 1. 会话级覆盖优先
const override = normalizeSendPolicy(params.entry?.sendPolicy);
if (override) return override;
// 2. 全局策略匹配
const policy = params.cfg.session?.sendPolicy;
if (!policy) return "allow";
// 3. 根据通道和聊天类型匹配规则
// ...
}💡 最佳实践:对于面向公众的群聊通道,建议将
sendPolicy配置为受限模式,只允许 Agent 在被 @ 或直接回复时才发送消息。这可以通过session.sendPolicy按通道和聊天类型精确控制,避免 Agent 在群聊中过度活跃。
这种分层策略允许:
- 全局默认允许发送
- 对特定通道(如 WhatsApp 群组)设置限制
- 对个别会话进行例外处理
5.1.5 输入来源追踪
src/sessions/input-provenance.ts 追踪每条输入消息的来源,这对审计和调试至关重要。系统区分以下来源:
- 用户直接输入:通过通道发送的消息
- 系统事件:心跳、定时任务触发
- 子 Agent 回传:Sub-agent 完成后的结果
5.2 上下文窗口管理
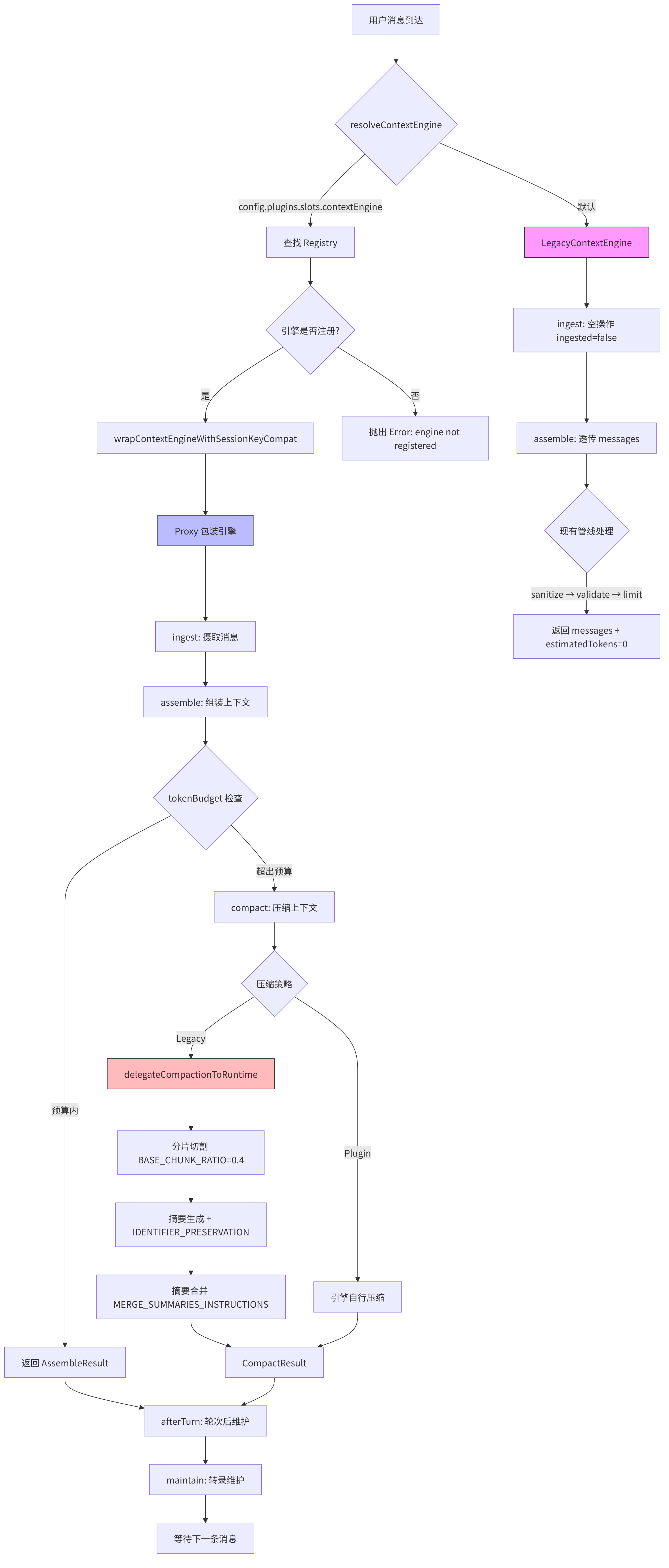
什么是 Context Engine? Context Engine(上下文引擎)是 OpenClaw 中负责管理对话历史的核心组件。它解决的根本问题是:LLM 的上下文窗口有限(通常 128K-200K tokens),但用户的对话可以无限延续。Context Engine 就像一位图书管理员——它不可能把图书馆的所有书搬到你面前,但它能确保你需要的那几本书始终在手边。它负责消息的摄取(ingest)、组装(assemble)、压缩(compact),以及决定哪些历史消息值得保留、哪些可以被摘要替代。
图 5-2:上下文窗口管理流程
下图展示了 src/context-engine/ 中上下文从摄取到组装再到压缩的完整处理流程,包括 Legacy 引擎的委托路径和插件引擎的完整路径。
5.2.1 一个具体的数字示例
在深入接口之前,让我们用具体数字理解上下文窗口管理的挑战:
假设你使用 Claude Opus(200K token 窗口),和 Agent 进行一天的工作对话:
text
系统提示词(SOUL.md + AGENTS.md + 工具列表 + 技能列表) ≈ 8,000 tokens
上午 10:00 你发了 5 条消息 + Agent 回复 5 条 ≈ 3,000 tokens
上午 11:00 你让 Agent 读了一个 500 行的源码文件 ≈ 12,000 tokens
下午 14:00 讨论了 3 个 PR,Agent 执行了 8 次工具调用 ≈ 45,000 tokens
下午 16:00 又读了 2 个配置文件 + 调试一个 bug ≈ 30,000 tokens
下午 18:00 继续讨论架构设计 ≈ 25,000 tokens
───────────────────────────────────────────────────
累计已用 Token ≈ 123,000 tokens
安全预算 = 200K × 0.8(留 20% 给模型输出) = 160,000 tokens
剩余空间 ≈ 37,000 tokens