Appearance
第12章 定时任务与自动化
"演示 Agent 与生产 Agent 的区别往往不是智能——而是主动性。一个不会自己巡逻的保安,和一个等你喊了才来的消防员,本质上一样不可靠。"
本章要点
- 理解被动 Agent 与主动 Agent 的哲学分野
- 掌握三种自动化机制:Cron 定时触发、心跳周期检查、事件钩子响应
- 理解三种机制的协同选择策略与适用场景
- 思考主动 Agent 的伦理考量与安全边界
前两章赋予了 Agent 行动的能力:工具系统是软件层的双手,Node 系统是物理层的感官。但这些能力都有一个共同的前提——需要有人发起请求。如果没有人说话,Agent 就安静地等着。
一个真正有用的助手,不应该只会接球,还要会主动传球。
12.1 被动 Agent 与主动 Agent 的哲学分野
12.1.1 问题的本质
大多数 Agent 框架将 Agent 设计为响应式系统:用户提问,Agent 回答。一问一答,周而复始。这种设计背后的假设是——Agent 是工具,工具等待使用。
但想象一个真正优秀的助手会做什么——早上八点,你还没醒,它已经检查了收件箱中的紧急邮件、扫描了 GitHub 上的关键 Issue、审查了服务器指标,并在 Telegram 中留下一条精炼的摘要:"一切正常,但 staging 磁盘使用率达到 87%——建议今天清理。"
这不是被动响应,而是主动巡逻。就像一位尽职的夜间保安,不需要有人报警才巡楼,而是按时按路线主动巡查,发现异常才叫醒你。
被动的 Agent 是秘书——电话响了才接。主动的 Agent 是管家——你醒来时咖啡已经泡好,日程已经整理完毕,车已经预热。
🔥 深度洞察:主动性是智能的试金石
从认知科学的角度看,被动响应与主动行动之间的鸿沟,恰恰是反射弧与前额叶皮层的区别。膝跳反射是被动的——刺激来了,反应就来。但人类的真正智能体现在"预判"——看到乌云就带伞,不需要等到淋湿。这种预判能力在军事中叫做"OODA 循环"(观察-定向-决策-行动),其核心洞察是:谁能更快完成循环,谁就掌握主动权。OpenClaw 的 Cron/心跳/钩子三件套,本质上就是 Agent 的 OODA 循环基础设施——Cron 是定时"观察",心跳是条件"定向",钩子是事件"决策"。没有这套基础设施,Agent 永远在被动反应;有了它,Agent 开始真正"思考"时间维度上的策略。
12.1.2 "如果不这样设计会怎样?"
假设 OpenClaw 只有响应式能力,没有任何自动化机制。运营者想实现"每天早上 9 点发送待办总结",唯一的办法是:
方案 A:外部 Cron + API 调用。在系统 crontab 中添加一条规则,调用 OpenClaw 的 HTTP API 发送消息。问题:系统 cron 不了解 Agent 的上下文(当前模型、活跃会话、技能配置);每次调用都是无状态的"冷启动";需要管理两套配置(系统 cron + OpenClaw)。
方案 B:持久脚本。写一个 Python 脚本,循环等待到 9 点然后调用 API。问题:又一个需要部署、监控和维护的进程;崩溃了谁来重启它?
方案 C:运营者手动触发。每天早上手动问 Agent。问题:这正是我们试图自动化的事情——让人去触发自动化本身就是反模式。
三种方案都不令人满意,因为它们把"何时行动"的决策放在了 Agent 之外。Agent 知道自己有哪些技能、连接了哪些通道、当前用什么模型——它是最适合做调度决策的实体。定时任务应该是 Agent 的内建能力,而非外部附加物。
12.1.3 主动性的三个维度
实现主动性需要大多数框架完全缺乏的基础设施:
- 时间感知:在特定时间或间隔触发动作的能力。
- 条件判断:判断是否值得行动——不是每次都要做事,有时"一切正常"也是有价值的信息。
- 打扰智能:判断何时值得打扰人类、何时应该保持沉默——凌晨三点的非紧急通知不是贴心,而是骚扰。
OpenClaw 提供三种互补机制来满足这些维度:Cron 调度(精确时间触发)、心跳(周期性条件检查)和自动回复钩子(事件触发)。三者各有侧重,协同构成 Agent 主动性的完整基础设施。
关键概念:主动 Agent(Proactive Agent) 主动 Agent 不仅响应用户消息,还能在无人触发的情况下自主执行任务——定时巡检、定期报告、条件触发通知。OpenClaw 通过内置的 Cron 调度器、心跳机制和事件钩子三种机制实现主动性,让 Agent 从"等待指令的秘书"进化为"主动巡逻的管家"。

12.2 Cron:精确的时间触发
12.2.1 设计哲学:为什么不用系统 Cron?
OpenClaw 的 Cron 系统(src/cron/service.ts)运行在网关进程内部,使用 Node.js 定时器而非系统级 cron。这个选择看似违反"不要重新发明轮子"的原则——系统 cron 已经存在了 50 年,久经考验。为什么要自己实现?
原因1:上下文访问。系统 cron 只能启动外部命令。OpenClaw 的 Cron 作业需要完全访问 Agent 上下文——当前会话、加载的技能、可用的模型、活跃的通道。这些上下文在网关进程内部,外部 cron 无法访问。
原因2:配置统一。运营者在 openclaw.yaml 中一站式管理所有配置。如果定时任务在系统 crontab 中,运营者需要维护两套配置,且两者的语法、部署流程和故障排查方式完全不同。
原因3:跨平台一致。系统 cron 在 Linux、macOS 和 Windows 上实现不同。OpenClaw 需要在所有平台上提供一致的行为。
⚠️ 注意:Cron 任务和心跳任务共享同一个 Agent 上下文(模型、工具、安全策略),但使用独立的 Session。这意味着 Cron 任务中的对话历史不会与用户的主对话混在一起。但要注意——如果 Cron 任务触发了大量 LLM 调用,它会消耗与用户对话相同的 API 配额。
原因4:热重载。修改 openclaw.yaml 中的 Cron 配置后,无需重启网关即可生效。系统 cron 虽然也能热重载,但需要额外的同步逻辑。
权衡:网关停止时 Cron 作业也停止。系统 cron 不受应用状态影响——即使网关崩溃,cron 仍然准时触发。但对于 Agent 任务,网关不运行意味着 Agent 本身不可用,触发一个无法执行的任务没有意义。
⚠️ 常见陷阱:Cron 表达式的时区问题
OpenClaw 的 Cron 表达式在运营者的本地时区解释。如果你的服务器设置为 UTC,而你期望"每天早上 9 点北京时间"执行,需要转换为 UTC 时间:
json5// ❌ 错误:服务器时区为 UTC 时,这是 UTC 9:00(北京 17:00) { "schedule": "0 9 * * *" } // ✅ 正确:设置 TZ 环境变量或使用 UTC 偏移 // 方法 1:在 systemd unit 中设置 TZ=Asia/Shanghai // 方法 2:计算 UTC 偏移 → 北京 9:00 = UTC 1:00 { "schedule": "0 1 * * *" }最安全的做法是通过
TZ环境变量统一服务器时区,避免心算转换。
⚠️ 常见陷阱:Cron 任务和用户对话共享 API 配额
Cron 任务使用独立的 Session,但共享相同的 Auth Profile 和 API 密钥。如果你配置了 10 个 Cron 任务每小时执行一次,高峰期可能与用户对话争抢 API 配额,导致用户对话触发 429 限流。建议:
- 将 Cron 任务的模型设置为低成本模型(如
claude-haiku)- 错开 Cron 任务的执行时间,避免同时触发
- 为 Cron 任务配置独立的 Auth Profile(如果有多个 API Key)
12.2.2 调度循环的设计
核心调度循环(src/cron/service.ts)的设计追求正确性而非效率——对于每分钟只有几个事件的调度系统,正确性远比纳秒级性能重要。
typescript
// src/cron/service.ts(核心调度逻辑,简化)
private armMainTimer(): void {
const nextWakeTime = nextWakeAtMs(this.state);
const delay = Math.max(0, nextWakeTime - Date.now());
this.timer = setTimeout(async () => {
await this.executeDueJobs();
this.armMainTimer(); // 为下一个作业重新设置
}, delay);
}这个设计有几个值得注意的特性:
单定时器策略:不是为每个作业设置独立的定时器(这会在作业数量增长时创建大量定时器),而是只维护一个定时器,指向最近的下一次触发。触发后,执行所有到期作业,然后重新计算下次触发。
为什么不用 setInterval? setInterval 以固定间隔触发,不考虑执行时间。如果检查间隔是 1 分钟但执行耗时 2 分钟,任务会堆叠。setTimeout 链保证上一次执行完成后再计算下一次——虽然可能微小漂移,但避免了任务风暴。
时区处理:Cron 表达式(如 "0 9 * * 1-5")在运营者的本地时区解释,而非 UTC。这看似小事,但"每天早上 9 点"对北京用户和纽约用户意味着不同的 UTC 时间。
12.2.3 重启恢复:错过的作业怎么办?
这是任何非系统级调度器必须回答的关键问题:如果网关在凌晨 2 点到 5 点停机,而有一个 3 点的作业,启动时应该补执行吗?
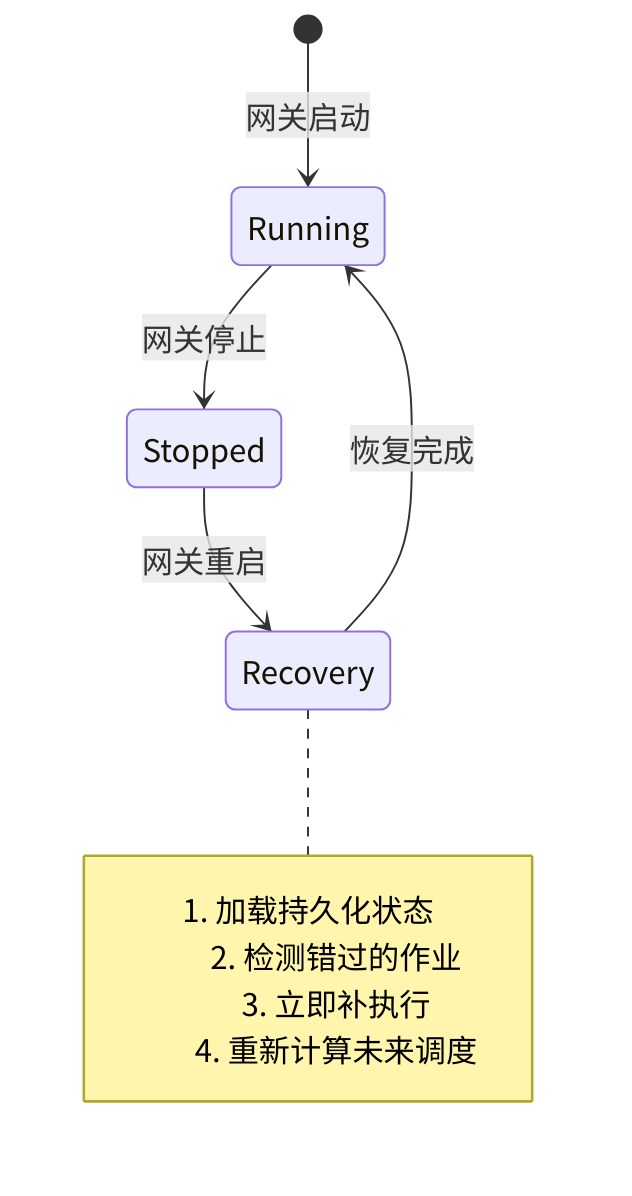
OpenClaw 的答案是**"启动追赶"(catch-up on start)**:Cron 服务在启动时加载持久化状态,检测每个作业的"上次执行时间"和"应该执行的时间",对于错过的作业立即补执行。
但这里有一个微妙的设计决策:如果停机了 24 小时,一个每小时触发的作业应该补执行 24 次吗?答案是否。系统只补执行最近一次错过的触发——24 小时前的小时级监控数据已经没有意义了。这是"追赶"和"重放"的区别:追赶是恢复到当前状态,重放是试图重现历史。
12.2.4 逐作业模型选择
逐作业模型选择是一个容易低估的功能:
yaml
cron:
jobs:
daily-report:
schedule: "0 9 * * 1-5" # 工作日早上 9 点
agent: main
message: "总结昨天的活动和待办任务"
channel: telegram
model: "anthropic/claude-sonnet-4-20250514" # 摘要需要高质量模型
health-check:
schedule: "*/15 * * * *" # 每 15 分钟
agent: main
message: "检查 https://example.com 是否响应。如果宕机则告警。"
model: "openai/gpt-4o-mini" # 健康检查不需要强模型
disk-cleanup:
schedule: "0 3 * * *" # 每天凌晨 3 点
agent: main
message: "清理 /tmp 中超过 7 天的文件。"
# 不指定 model → 使用 Agent 默认模型这种设计的成本影响是显著的。一个每 15 分钟运行的健康检查,使用 Claude Opus 每月可能花费数百美元。使用 GPT-4o-mini,同样的任务每月不到 5 美元。模型选择不是性能参数——它是成本参数,对于频繁运行的作业,差异可能是 100 倍。