Appearance
第18章 构建你自己的 Agent 帝国
"单 Agent 的天花板不是智能不够,而是上下文不够。200K token 听起来很多,但一次深度代码审查就能吃掉 80K——还没开始回复,预算已经过半。多 Agent 编排的本质,是用进程隔离换上下文空间。"
本章要点
- 理解单 Agent 天花板的四个根本限制
- 掌握树形编排模型与四种编排策略(委托、管线、竞争、混合)
- 深入多 Agent 编排的核心难题:状态共享、故障传播、资源竞争
- 规划从单 Agent 到 Agent 帝国的演进路径
18.1 从齿轮到机器
十七章,我们在源码层面逐一解剖了 OpenClaw 的每一个齿轮和螺钉——从 Gateway 的生命周期管理到 Provider 的模型降级,从 Session 的上下文压缩到安全系统的纵深防御。每个组件都已了然于胸。
但零件堆在桌上不是机器。最后一章,我们将视线从微观拉升到宏观:如何将这些精密组件组装成一台运转的机器——一个你自己的 Agent 帝国?
理解每一个音符不等于能演奏交响曲。本章讲的是指挥的艺术——何时让铜管齐鸣,何时让弦乐独唱,何时所有声部在一个和弦上交汇。
18.2 单 Agent 天花板:四个根本限制
大多数人从单 Agent 开始——配置一个 Agent,连接一个通道,分配一个模型。这在简单场景下完美工作。但随着任务复杂度增长,单 Agent 会撞上四面墙:
18.2.1 上下文耗尽
即使 200K token 的上下文窗口也可能不够完成需要同时研究、编码和沟通的复杂任务。一次深度代码审查可能消耗 50K token 的代码内容 + 20K token 的讨论历史 + 10K token 的系统提示和技能——80K token 用完了,Agent 还没开始回复。
量化分析:假设一个"全栈任务"——研究技术方案(读 5 篇文章 × 5K token = 25K)、编写代码(读 10 个文件 × 3K token = 30K)、提交 PR 并写说明(5K)。仅输入就需要 60K token。如果上下文窗口是 128K,留给推理和对话历史的只有 68K——而且这还没算系统提示和工具定义。
18.2.2 焦点稀释
一个 Agent 同时处理编码、搜索和沟通,不如三个专家。系统提示因每种场景的指令而臃肿。
反事实分析:想象一个系统提示同时包含"代码风格指南"(2K token)、"搜索策略"(1K token)、"沟通礼仪"(1K token)和"安全规则"(1K token)。如果 Agent 在编码,后三项的 3K token 完全是浪费。在三个专业 Agent 中,每个只需要与其角色相关的指令——token 利用率提高了 3-4 倍。
18.2.3 无并行性
独立子任务顺序执行。可以并行五个搜索的研究任务却要逐个等待。
时间成本:5 个搜索 × 每个 10 秒 = 50 秒(顺序)vs. 10 秒(并行)。在一个包含 20 个独立子任务的复杂工作流中,并行 vs. 顺序的差异可能是 5 分钟 vs. 45 分钟。
18.2.4 单点故障
模型调用在任务中途失败,整个工作流停止。单 Agent 中没有"部分完成"的概念——要么全部成功,要么从头再来。
多 Agent 编排突破了全部四个限制。但它引入自己的挑战——这些挑战是本章的核心主题。
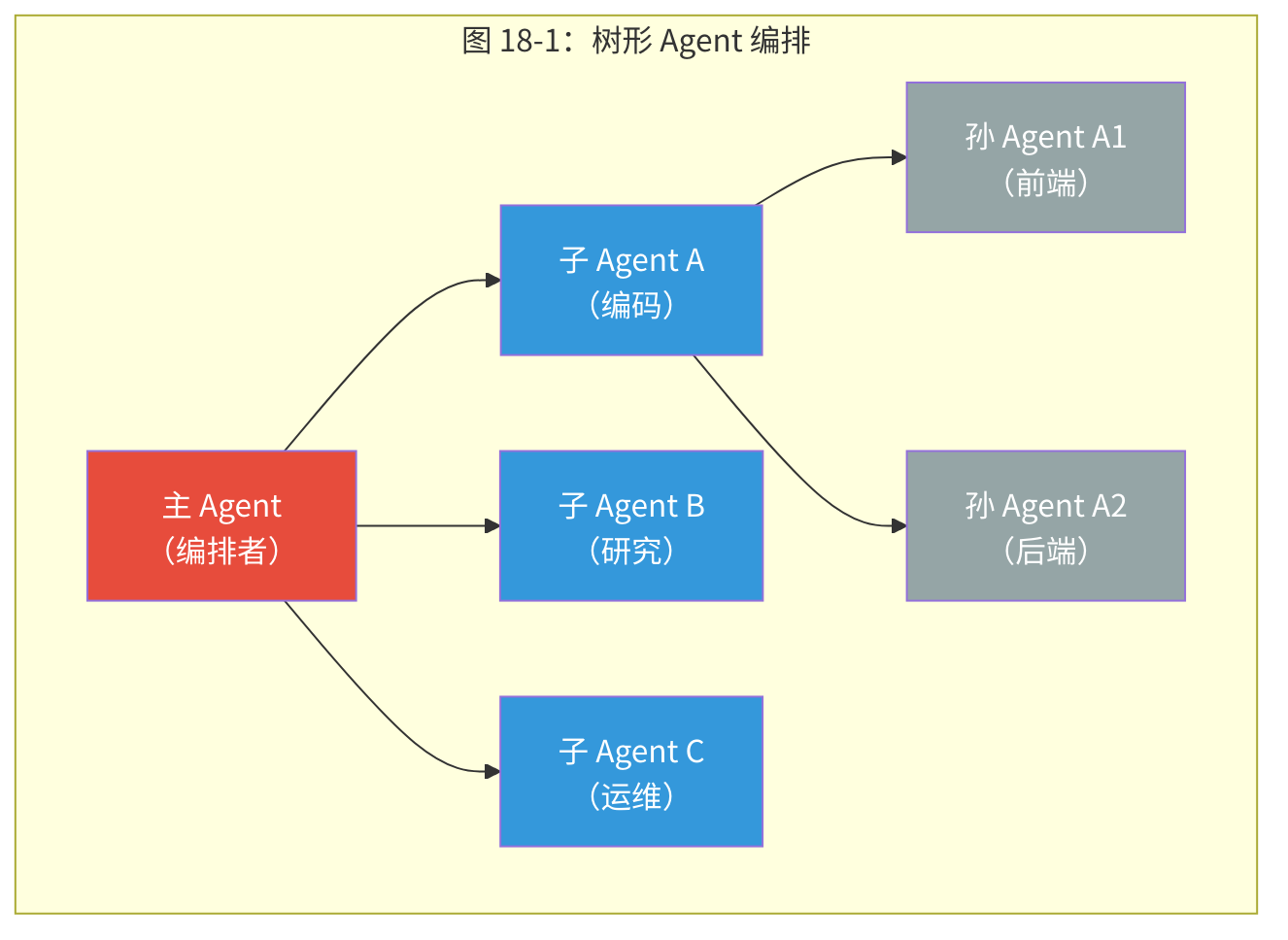
关键概念:树形编排模型(Tree Orchestration) OpenClaw 的多 Agent 编排采用树形结构——主 Agent 生成子 Agent,子 Agent 可进一步生成孙 Agent,层级有可配置的深度限制。选择树而非图的原因是:树形结构保证了清晰的父子关系、单一的控制链和可预测的资源管理。图形拓扑(任意 Agent 间通信)虽然更灵活,但会带来死锁风险、审计困难和资源管理的组合爆炸。
💡 最佳实践:从单 Agent 开始,只在遇到明确的瓶颈(上下文耗尽、焦点稀释、需要并行性)时才引入多 Agent 编排。过早的多 Agent 设计会增加调试复杂度和 Token 消耗——每个子 Agent 都需要独立的系统提示和上下文窗口。
🔥 深度洞察:多 Agent 编排的本质是组织设计,不是技术实现
单 Agent 到多 Agent 的跃迁,表面上是技术问题(如何 spawn 子进程、如何传递上下文),本质上却是组织设计问题。管理学家 Herbert Simon 在 1960 年代研究组织结构时发现:人类组织采用层级结构不是因为命令效率高,而是因为层级是管理复杂度的最经济方式——每一层只需理解自己下一层的接口,而非整个系统。OpenClaw 的树形 Agent 编排重新发现了同一条真理:主 Agent 不需要理解子 Agent 的内部推理,只需要理解它返回的结果。这不是巧合——任何系统在复杂度超过单个处理单元的认知能力时,都会自发演化出层级结构,无论这个处理单元是人、细胞还是 AI Agent。你不是在"设计" Agent 架构——你是在为 AI 劳动力做组织设计。招聘、分工、汇报关系、绩效评估——这些概念在 Agent 编排中一一对应。
18.3 树形编排:OpenClaw 的多 Agent 模型
18.3.1 为什么是树而不是图?
OpenClaw 的多 Agent 模型是一棵树:主 Agent 生成子 Agent,子 Agent 可以进一步生成孙 Agent,有可配置的深度限制。
替代方案是图(任意 Agent 之间的通信)。为什么不选图?
图的问题1:死锁。Agent A 等待 Agent B 的结果,Agent B 等待 Agent A 的结果。在树中,通信只能沿着边(父→子或子→父)发生,消除了循环依赖的可能。
图的问题2:责任不清。如果 Agent A 和 Agent B 同时修改了同一个文件,谁的版本生效?在树中,父 Agent 协调子 Agent,天然是冲突的仲裁者。
图的问题3:调试地狱。在图中追踪"这个决策是怎么做出的"可能需要遍历整个图。在树中,因果链是从根到叶的清晰路径。
权衡:树限制了通信灵活性——兄弟 Agent 之间不能直接通信(必须通过父 Agent 中继)。但这种限制恰好强制了一个健康的架构属性:每个 Agent 都有明确的上级,避免了"谁负责"的歧义。
18.3.2 两种生成模式
OpenClaw 提供两种子 Agent 生成模式:
run 模式(一次性执行):子 Agent 执行任务,返回结果,自动清理。类似函数调用——有输入,有输出,执行后消失。
text
主 Agent → spawn(run, "翻译这段文字为英文") → 子 Agent 执行 → 返回翻译 → 子 Agent 销毁session 模式(持久会话):子 Agent 完成任务后保持活跃。可以后续发送更多消息。类似启动一个服务——它持续运行直到显式终止。
text
主 Agent → spawn(session, "你是代码审查专家") → 子 Agent 常驻 → 可以多次发送代码审查请求选择哪种模式取决于任务的交互性:一次性结果用 run;需要多轮交互用 session。
18.3.3 推送式完成通知
这在第17章已经从模式角度分析过,这里从实践角度补充。
子 Agent 完成时,结果作为普通消息回合投递给父 Agent——无轮询循环、无浪费 API 调用。完成通知通过子 Agent 注册表管理:
| 机制 | 细节 |
|---|---|
| 重试 | 1s → 2s → 4s → 8s 退避,最多 3 次 |
| 过期 | 完成通知 30 分钟硬限制 |
| 幂等 | 通知 ID 去重 |
| 宽限 | 15 秒内的投递错误不标记为失败 |
为什么有 30 分钟硬限制? 如果完成通知 30 分钟内未能投递,说明父 Agent 可能已经崩溃或已遭清理。继续重试只是浪费资源。运营者可以通过审计日志发现和处理这种情况。
18.3.4 ACP:跨进程 Agent 通信
Agent 通信协议(ACP)将子 Agent 编排扩展到外部进程。这意味着 OpenClaw 不仅可以编排自己的 Agent,还可以编排 Claude Code、Codex、OpenCode 等外部 Agent 运行时。
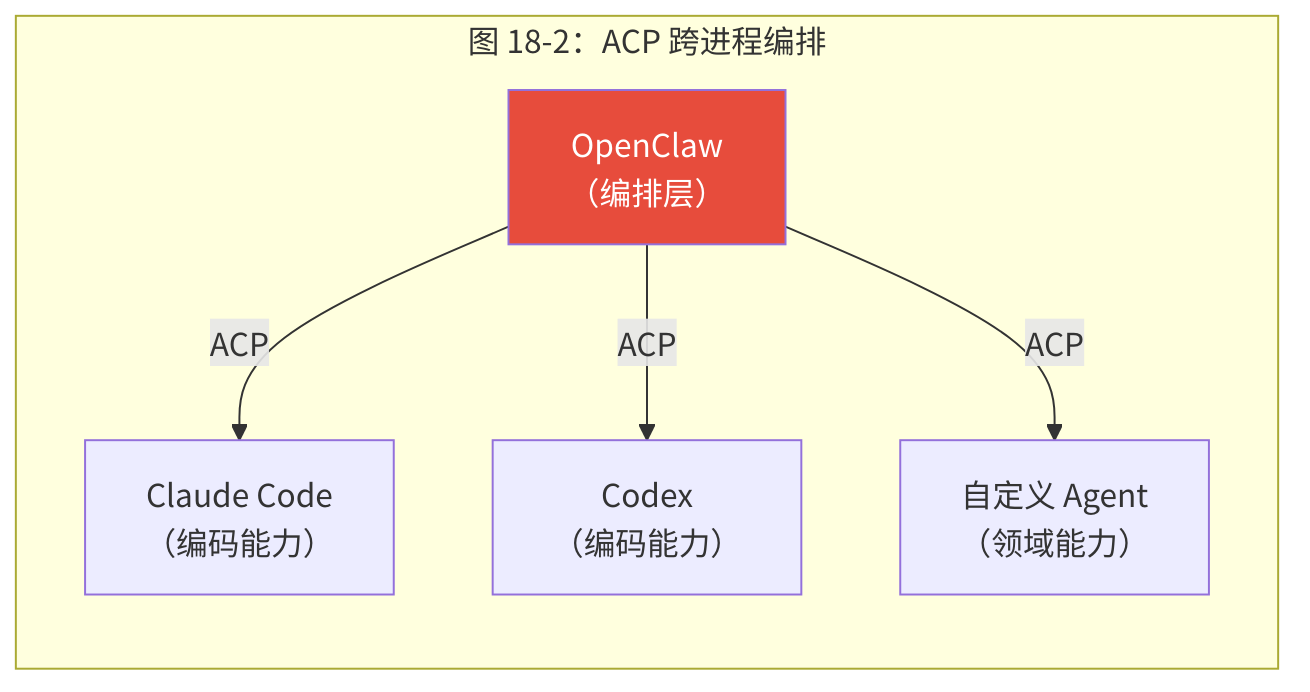
ACP 的关键设计决策是使用 stdin/stdout 作为传输层——这是最通用的进程间通信方式,几乎所有编程语言和操作系统都支持。不需要特殊的 SDK 或运行时——只要一个进程能从 stdin 读 JSON 并向 stdout 写 JSON,OpenClaw 就能编排它。
这将 OpenClaw 从单体运行时转变为编排层——它不需要自己实现所有 Agent 能力,而是协调最适合每项任务的 Agent 运行时。
18.4 编排模式:四种策略
18.4.1 顺序式编排
步骤逐一执行。简单可靠,但不利用并行性。
text
步骤1:研究技术方案 → 步骤2:编写代码 → 步骤3:编写测试 → 步骤4:提交 PR适用场景:步骤之间有严格依赖——后一步需要前一步的输出。