Appearance
第16章 技能系统
"上下文窗口是公共牧场——每个技能都想放更多的羊。全量加载 60 个技能消耗 48,000 token,按需加载只需 3,000。这不是优化技巧,而是'公地悲剧'的系统性解法。"
本章要点
- 理解技能系统如何解决知识注入的"系统提示膨胀"问题
- 掌握技能的剖析结构:SKILL.md 约定、六源加载与分层覆盖
- 深入过滤管线:从发现到提示注入的完整链路
- 理解技能安装安全、调用控制与生命周期管理
- 实战演练:从零编写一个完整的技能包
部署方案解决了"在哪里跑"的问题,接下来要解决"怎么让 Agent 变得更聪明"。第 9 章的插件系统让平台可扩展,本章的技能系统则让 Agent 本身可扩展——不是改代码,而是给它"教材"。
16.1 知识注入问题
16.1.1 陈述性知识 vs. 程序性知识
问 Claude:"北京今天天气怎么样?"它会给你一个充满免责声明的模糊回答——"我无法获取实时数据,但通常三月份的北京……"。给它一个天气技能,结果截然不同——它直接调用 curl wttr.in/Beijing,返回精确的温度、湿度和未来三天预报。
差别在哪?大语言模型拥有广泛的陈述性知识("知道什么"),但缺乏程序性知识("怎么做")。哪个命令检查磁盘使用?某个 API 的参数格式是什么?GitHub CLI 怎么创建 PR?这些答案躺在 Stack Overflow 和 man pages 里,不在模型权重里。
技能系统弥合的,正是这道鸿沟——把"怎么做"的知识注入到"知道什么"的模型中。
如果说模型的权重是"通识教育",技能就是"职业培训"。通识教育让你知道世界上有锁这种东西,职业培训教你拿哪把钥匙开哪扇门。
16.1.2 为什么不把所有知识放进提示?
最朴素的方案是:把所有技能的完整指令放进系统提示。Agent 启动时加载所有知识,像一个读过所有手册的专家。
这个方案的致命缺陷是上下文窗口是寸土寸金的共享资源。技能指令、系统提示、对话历史、工具结果和用户消息,都在争夺同一块 token 预算。
让我们做一个具体计算:
- 一个典型的技能 SKILL.md 约 800 token
- 一个活跃的 OpenClaw 实例可能有 60 个技能
- 全量加载:60 × 800 = 48,000 token
- 128K token 上下文窗口中,技能就占了 37.5%
- 剩余空间要容纳系统提示(~5,000)、对话历史(~30,000)、工具结果(变化)和用户消息
- Agent 实际推理的空间遭到严重挤压
更糟糕的是,大多数技能在大多数对话中都不会用到。如果用户在讨论代码审查,60 个技能中可能只有 github 和 coding-agent 两个相关。剩余 58 个技能白白占用了 46,400 token 的上下文空间——这是巨大的浪费。
16.1.3 按需加载:图书馆模型
OpenClaw 对这一张力的回应,是技能系统最精妙的设计:按需加载。
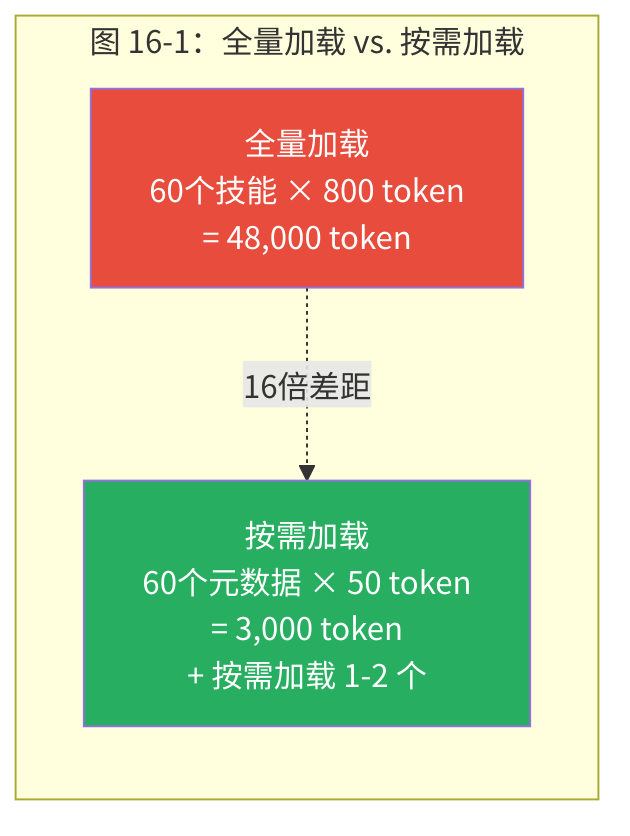
只有技能元数据(名称 + 描述,每个约 50 token)永久驻留在系统提示中,扮演"目录"的角色。完整指令仅在模型判断需要激活某个技能时才加载。60 个技能的场景下,提示开销从约 48,000 token 骤降至约 3,000 token——16 倍的效率提升。
这就像图书馆只在书架上放目录卡片,读者选定后才从书库取出原书。你不会把整个图书馆搬到办公桌上才开始工作——你只需要知道哪本书在哪个书架上。目录告诉你"这本书存在,关于什么",但不包含书的内容。只有你决定"我需要这本书"时,图书馆才把它拿出来。
关键概念:按需加载(On-Demand Loading) 技能系统的按需加载机制只在系统提示中放置技能的元数据摘要(名称 + 描述,约 50 token/个),完整的技能指令仅在模型判断需要时才加载。这将 60 个技能的 Token 开销从约 48,000 降至约 3,000——16 倍的效率提升。这一设计解决了"公地悲剧"问题:上下文窗口是公共资源,每个技能都想占用更多空间,按需加载确保只有真正需要的技能才消耗宝贵的 Token 预算。
🔥 深度洞察:技能系统是生态位理论的工程实现
生态学中有个核心概念叫生态位(Ecological Niche):一片森林中,不同物种占据不同的生态位——有的在树冠层光合作用,有的在林下层分解落叶,有的在土壤中固氮。它们共享同一片有限的资源(阳光、水分、养分),但通过分工避免了零和竞争。OpenClaw 的技能系统面对的正是同一道难题:60 个技能共享一个有限的上下文窗口(相当于森林中有限的阳光),如果每个技能都试图"全量展开",就像所有树都长到同一个高度争夺阳光——结果是谁都长不好。按需加载的本质是让每个技能找到自己的生态位:元数据目录是"种子库",模型的选择是"自然选择",只有与当前任务匹配的技能才"萌发"并占据上下文空间。这不是工程优化——这是在有限资源上实现最大生物多样性的生存策略。
16.1.4 按需加载的挑战
按需加载不是免费的午餐,它引入了一个新的复杂度:模型必须能从 50 token 的描述中准确判断是否需要某个技能。
如果描述写得太笼统("适用于各种编程任务"),模型可能在不需要时加载它。如果描述写得太具体("仅适用于 Python 3.11 的 asyncio 调试"),模型可能在需要时错过它。描述的质量直接决定了按需加载的效果。
OpenClaw 通过规范化的描述格式来缓解这个问题:
yaml
description: "通过 wttr.in 获取天气和预报。
适用:用户询问天气、温度或预报。
不适用:历史天气数据或严重天气警报。"💡 最佳实践:编写技能描述时,始终包含"适用"和"不适用"两个维度。这帮助模型准确判断何时加载技能,避免误触发(浪费 Token)和漏触发(功能缺失)。好的描述应该让模型在 50 token 内做出准确的加载决策。
注意"适用"和"不适用"的明确界定——这不是随意的写作风格,而是帮助模型做精准判断的结构化信息。
16.2 技能的剖析
16.2.1 SKILL.md 的结构
每个技能是一个目录,包含必需的 SKILL.md 文件:
yaml
---
name: weather
description: "通过 wttr.in 获取天气和预报。
适用:用户询问天气、温度或预报。
不适用:历史天气数据或严重天气警报。"
metadata:
openclaw:
emoji: "☔"
requires:
bins: [curl] # 需要 curl 命令
env: [WEATHER_API_KEY] # 可选的 API 密钥
platform: [linux, darwin] # 支持的平台
---
# 天气技能
## 使用方法
```bash
curl wttr.in/Beijing # 当前天气
curl wttr.in/Beijing?format=3 # 紧凑格式注意事项
- 如果用户没有指定城市,使用 USER.md 中记录的位置
- 使用
?format=j1获取 JSON 格式以便程序化处理
text
关键设计决策:**只有 `name` 和 `description` 进入系统提示**。Markdown 正文仅在模型决定使用该技能后才加载。YAML frontmatter 中的元数据用于**资格过滤**——在技能出现在目录之前就判断它是否适用于当前环境。
### 16.2.2 为什么用 Markdown 而非代码?
这个设计选择引发了最多讨论。LangChain 用 Python 类定义工具。Semantic Kernel 用函数签名。为什么 OpenClaw 用纯文本的 Markdown 文件?
**方案 A:Python/TypeScript 代码**
```python
class WeatherTool:
def __init__(self):
self.name = "weather"
self.description = "Get weather forecasts"
def execute(self, city: str) -> str:
return subprocess.run(["curl", f"wttr.in/{city}"], capture_output=True).stdout优点:类型安全,可编程,IDE 支持。缺点:需要编程能力,有运行时安全风险(代码可以做任何事),修改需要重新部署。
方案 B:JSON/YAML 配置
yaml
name: weather
description: "Get weather forecasts"
commands:
- pattern: "weather {city}"
exec: "curl wttr.in/{city}"优点:声明式,安全。缺点:表达能力有限(复杂逻辑难以用 YAML 表达),不够灵活。
方案 C:Markdown(OpenClaw 的选择)
优点有三个层面:
- 门槛极低:能写 README 的人就能写技能。领域专家(网络管理员、数据分析师、运维工程师)无需学习 SDK 就能将自己的专业知识编码为技能。
- 执行安全:Markdown 文件是惰性的——它不是代码,系统不会执行它。恶意技能可能提供错误指令,但无法直接入侵系统。安全边界清晰:技能能做的最坏事情是误导 Agent,而非直接运行恶意代码。
- LLM 原生格式:技能是提示片段——设计目标是让 LLM 消费而非运行时解释器。Markdown 是 LLM 最自然的输入格式。格式与消费者的对齐消除了翻译层。
权衡:Markdown 缺乏类型检查和编程抽象。复杂的工作流难以用纯文本描述。OpenClaw 通过 command-dispatch: tool 和脚本引用(技能目录中可以包含辅助脚本)来部分弥补这个缺陷。
⚠️ 常见陷阱:SKILL.md 的 YAML Frontmatter 格式错误
SKILL.md 的 YAML frontmatter 必须以
---开头和结尾。常见错误:markdown<!-- ❌ 错误:缺少结束的 --- --> --- name: my-skill description: "这是我的技能" # 技能正文 ... <!-- ❌ 错误:description 中包含未转义的冒号 --> --- name: my-skill description: 这是我的技能: 很好用 --- <!-- ✅ 正确:冒号需要引号包裹 --> --- name: my-skill description: "这是我的技能: 很好用" ---YAML 解析失败时,整个技能会被静默忽略——你不会看到报错,只是技能不出现在目录中。如果新添加的技能"不生效",首先检查 frontmatter 格式。
⚠️ 常见陷阱:技能描述过于笼统导致误触发
按需加载依赖模型从 50 token 的描述中判断是否需要加载技能。描述太笼统会导致不必要的加载,浪费上下文空间:
yaml# ❌ 过于笼统:几乎任何请求都可能触发 description: "帮助用户完成各种任务" # ✅ 精确:明确适用和不适用场景 description: "通过 GitHub CLI 管理 PR 和 Issue。 适用:创建 PR、查看 CI 状态、合并 PR、创建 Issue。 不适用:代码编写、Git 本地操作(commit/push/branch)。"
16.3 六源加载与分层覆盖
16.3.1 六个来源的设计动机
OpenClaw 从六个来源加载技能,每个有不同优先级(从低到高):
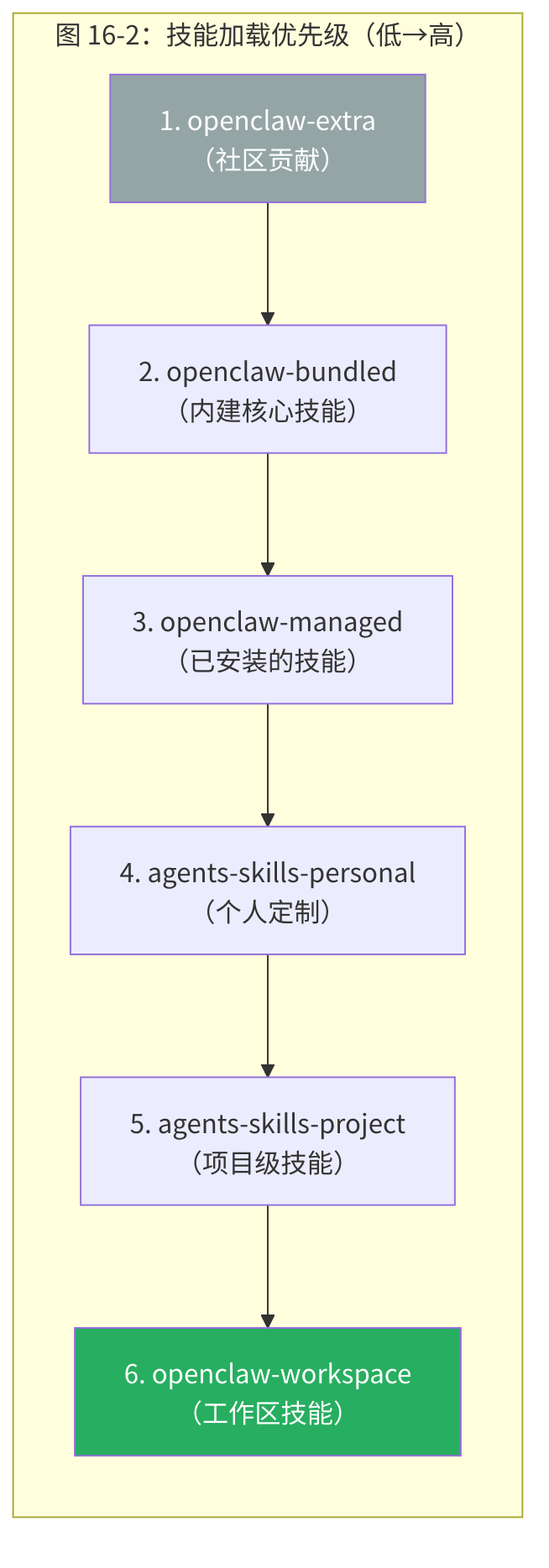
为什么需要六个来源?不同来源服务不同的定制需求:
| 来源 | 维护者 | 用途 |
|---|---|---|
| extra | 社区 | 第三方贡献的实验性技能 |
| bundled | OpenClaw 团队 | 核心技能(weather、github、coding-agent) |
| managed | 运营者 | 通过 openclaw skills install 安装的技能 |
| personal | 运营者 | 跨项目通用的个人技能 |
| project | 项目 | 特定项目的技能(如"这个项目的部署流程") |
| workspace | 工作区 | 当前工作区的技能(最高优先级) |
16.3.2 完全替换而非合并
高优先级来源完全替换同名的低优先级技能——没有合并。这是刻意的设计决策。
考虑替代方案:合并覆盖——高优先级来源只覆盖它定义的字段,低优先级的其他字段保留。这听起来更灵活,但引入了歧义:如果 bundled 的 weather 技能有 5 个命令,workspace 的 weather 技能只定义了 2 个,合并后有几个?7 个?还是 2 个?如果 workspace 想删除 bundled 的某个命令怎么办?